ISSN 2359-5191
ISSN 2359-5191
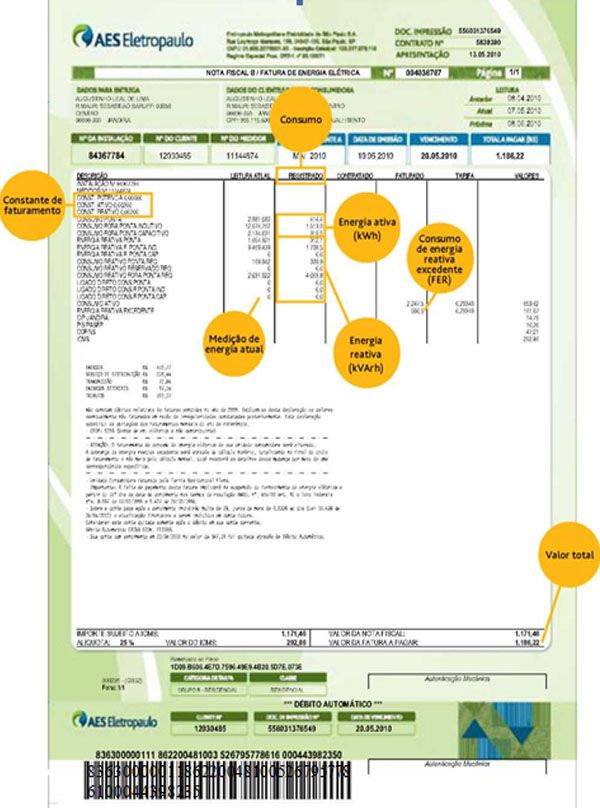
Uma pesquisa desenvolveu técnicas para reconhecimento de caracteres em documentos digitalizados. O professor Flavio Soares Corrêa da Silva, do Instituto de Matemática e Estatística da USP (IME/USP), juntamente com a empresa Opus Software, trabalhou para produzir conhecimento a respeito da área de processamento de imagens.
"Existem diversos sistemas para reconhecimento de caracteres em documentos digitalizados, mas eles não interpretam os caracteres reconhecidos e apresentam taxas de erros que, embora estatisticamente pequenas, podem comprometer a interpretação do texto obtido", explica o docente. "Nosso estudo teve como foco avaliar se conhecimento prévio a respeito da estrutura de um documento permitiria tanto melhorar a precisão do reconhecimento de texto como auxiliar na interpretação do texto reconhecido", completa ele.
A parceria com a Opus Software aconteceu de forma que a empresa foi tratada como um parceiro de pesquisas. "Ela tinha como um de seus interesses incorporar conhecimento a respeito da área de processamento de imagens, com foco específico em análise de documentos digitalizados", conta Silva. Durante o projeto, alguns funcionários jovens ficaram responsáveis pelos estudos e pela implementação de protótipos.
Os principais resultados do projeto foram publicados em um periódico científico internacional. A Opus Software foi bem sucedida na incorporação de conhecimento, tendo já utilizado as técnicas desenvolvidas na pesquisa em outros projetos de natureza comercial da empresa. O estudo desenvolvido em conjunto com o professor do IME/USP teve caráter científico. Seus resultados foram publicados e são de domínio público.
A pesquisa foi desenvolvida a partir de ferramentas de software que fazem uso de diversas soluções computacionais já existentes. A novidade está na forma como esses algoritmos foram utilizados, como uma ferramenta inovadora para o uso no reconhecimento de textos em imagens complexas.
Para o desenvolvimento do novo recurso, foram utilizadas contas de luz. Flavio Soares Corrêa da Silva explica que elas apresentam um layout bem definido, possibilitando identificar campos em que pode-se esperar encontrar, como valores numéricos com significados previamente conhecidos. “Com esses mecanismos, conseguimos identificar campos chave com precisão, interpretar os valores obtidos e possibilitar, por exemplo, a aferição se os valores cobrados estariam corretos”, exemplifica o docente.
Os estudos se basearam em dispositivos de baixo custo e, hoje, a Opus Software utiliza as técnicas desenvolvidas durante a pesquisa em outros projetos de natureza comercial da empresa. O desenvolvimento da tecnologia demorou cerca de dois anos.

Educação básica é alvo de livros organizados por pesquisadores uspianos

Pesquisa testa software que melhora habilidades fundamentais para o bom desempenho escolar

Pesquisa avalia influência de supermercados na compra de alimentos ultraprocessados



